Writing a C compiler in 500 lines of Python
A few months ago, I set myself the challenge of writing a C compiler in 500 lines of Python1, after writing my SDF donut post. How hard could it be? The answer was, pretty hard, even when dropping quite a few features. But it was also pretty interesting, and the result is surprisingly functional and not too hard to understand!
There's too much code for me to comprehensively cover in a single blog post2, so I'll just give an overview of the decisions I made, things I had to cut, and the general architecture of the compiler, touching on a representative piece of each part. Hopefully after reading this post, the code is more approachable!
 Decisions, decisions
Decisions, decisions
The first, and most critical decision, was that this would be a single-pass compiler. 500 lines is too spare to be defining and transforming an abstract syntax tree! What does that mean?
Most compilers: faffing around with syntax trees
Well, most compiler's internals look something like this:
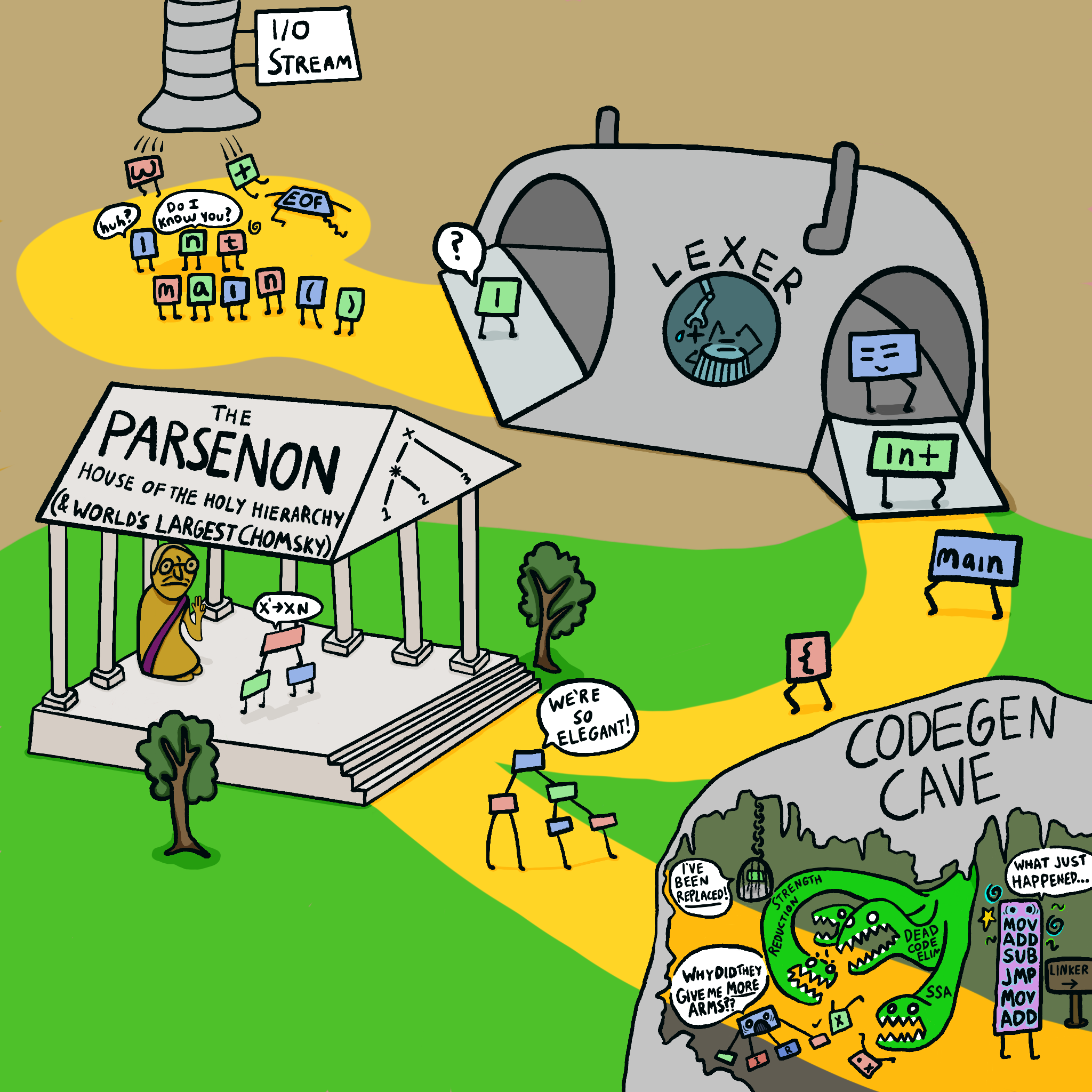
The tokens get lexed, then a parser runs over them and builds pretty little syntax trees:
# hypothetical code, not from anywhere
def parse_statement(lexer) -> PrettyLittleSyntaxTree:
...
if type := lexer.try_next(TYPE_NAME):
variable_name = lexer.next(IDENTIFIER)
if lexer.try_next("="):
initializer = parse_initializer(lexer)
else:
initializer = None
lexer.next(SEMICOLON)
return VariableDeclarationNode(
type = type,
name = variable_name,
initializer = initializer,
)
...
# much later...
def emit_code_for(node: PrettyLittleSyntaxTree) -> DisgustingMachineCode:
...
if isinstance(node, VariableDeclarationNode):
slot = reserve_stack_space(node.type.sizeof())
add_to_environment(node.name, slot)
if node.initializer is not None:
register = emit_code_for(node.initializer)
emit(f"mov {register}, [{slot}]")
...
The important thing here is that there are two passes. First the parsing builds up a syntax tree, then a second pass chews that tree up and turns it into machine code. That's really useful for most compilers! It keeps the parsing and codegen separate, so each can evolve independently. It also means that you can transform the syntax tree before using it to generate code—for example, by applying optimizations to it. In fact, most compilers have multiple levels of "intermediate representations" between the syntax tree and codegen!
This is really great, good engineering, best practices, recommended by experts, etc. But… it takes too much code, so we can't do it.
Instead, we'll be single-pass: code generation happens during parsing.
We parse a bit, emit some code, parse a bit more, emit a bit more code.
So for example, here's some real code from the c500 compiler for parsing the prefix ~ op:
# lexer.try_next() checks if the next token is ~, and if so, consumes
# and returns it (truthy)
elif lexer.try_next("~"):
# prefix() parses and generates code for the expression after the ~,
# and load_result emits code to load it, if needed
meta = load_result(prefix())
# immediately start yeeting out the negation code!
emit("i32.const 0xffffffff")
emit("i32.xor")
# webassembly only supports 32bit types, so if this is a smaller type,
# mask it down
mask_to_sizeof(meta.type)
# return type information
return meta
Notice there's no syntax trees, no PrefixNegateOp nodes.
We see some tokens and immediately spit out the corresponding instructions.
You may have noticed those instructions are WebAssembly, which leads us into the next section...
Using WebAssembly, for some reason?
So I decided to make the compiler target WebAssembly. I honestly don't know why I did this, it really didn't make it easier—I guess I was just curious? WebAssembly is a really weird target, especially for C. Besides the somewhat-external issues like spending a lot of time confused before I realized WebAssembly v2 is pretty different than WebAssembly v1, the instruction set itself is weird.
For one, there's no goto.
Instead, you have blocks—structured assembly, imagine that!—and "break" instructions that jump to either the beginning or end of a specific nesting-level of block.
This was basically inconsequential for if and while, but made implementing for extremely cursed, which we'll go over later.
Additionally, WebAssembly doesn't have registers, it has a stack, and is a stack machine. At first you might think that's awesome, right? C needs a stack! We can just use the WebAssembly stack as our C stack! Nope, because you can't take references to the WebAssembly stack. So instead, we need to maintain our own in-memory stack anyways, and then shuffle it on and off of the WASM parameter stack.
So in the end, I think I ended up with slightly more code than I would have needed to target a more normal ISA like x86 or ARM.
But it was interesting!
And theoretically, you could run code compiled with c500 in a browser, although I haven't tried (I just use the wasmer CLI).
Error handling
It basically doesn't.
There's a function die, which is called when anything weird happens and dumps a compiler stack trace—if you're lucky, you get a line number and a somewhat-vague error message.
------------------------------
File "...compiler.py", line 835, in <module>
compile("".join(fi)) # todo: make this line-at-a-time?
File "...compiler.py", line 823, in compile
global_declaration(global_frame, lexer)
<snip>
File "...compiler.py", line 417, in value
var, offset = frame.get_var_and_offset(varname)
File "...compiler.py", line 334, in get_var_and_offset
return self.parent.get_var_and_offset(name)
File "...compiler.py", line 336, in get_var_and_offset
die(f"unknown variable {n}", None if isinstance(name, str) else name.line)
File "...compiler.py", line 14, in die
traceback.print_stack()
------------------------------
error on line 9: unknown variable c
The Rust compiler, this is not :-)
What to drop
Finally, I had to decide what not to support, since it just wasn't feasible to get all of C into 500 lines. (sorry!) I decided I wanted a really decent sampling of features that tested what the general implementation approach was capable of—for example, if I had skipped pointers, I could have just gotten away with the WASM parameter stack and shed a lot of complexity, but that would have felt like cheating.
I ended up implementing the following features:
- arithmetic operations and binary operators, with proper precedence
int,short, andchartypes- string constants (with escapes)
- pointers (of however many levels), including correct pointer arithmetic (incrementing an
int*adds 4) - arrays (only single-level, not
int[][]) - functions
- typedefs (and the lexer hack!)
Notably, it doesn't support:
- structs :-( would be possible with more code, the fundamentals were there, I just couldn't squeeze it in
- enums / unions
- preprocessor directives (this would probably be 500 lines by itself...)
- floating point. would also be possible, the
wasm_typestuff is in, again just couldn't squeeze it in - 8 byte types (
long/long longordouble) - some other small things like pre/post cremements, in-place initialization, etc., which just didn't quite fit
- any sort of standard library or i/o that isn't returning an integer from
main() - casting expressions
The compiler passes 34/220 test cases in the c-testsuite. More importantly to me, it can compile and run the following program successfully:
int swap(int* a, int* b) {
int t;
t = *a; *a = *b; *b = t;
return t;
}
int fib(int n) {
int a, b;
for (a = b = 1; n > 2; n = n - 1) {
swap(&a, &b);
b = b + a;
}
return b;
}
int main() {
return fib(10); // 55
}
OK, enough about deciding things, let's get into the code!
Helper types
There's a small collection of helper types and classes that the compiler uses. None of them are particularly strange, so I'll pass over them fairly quickly.
Emitter (compiler.py:21)
This is a singleton helper to emit nicely-formatted WebAssembly code.
WebAssembly, at least the textual format, is formatted as s-expressions, but individual instructions don't need to be parenthesized:
(module
;; <snip...>
(func $swap
(param $a i32)
(param $b i32)
(result i32)
global.get $__stack_pointer ;; prelude -- adjust stack pointer
i32.const 12
i32.sub
;; <snip...>
)
)
Emitter just helps with emitting code with nice indentation so it's easier to read.
It also has a no_emit method, which will be used for an ugly hack later—stay tuned!
StringPool (compiler.py:53)
StringPool holds all the string constants so they can be arranged in a contiguous region of memory, and hands out addresses into that for the codegen to use.
When you write char *s = "abc" in c500, what really happens is:
StringPoolappends a null terminatorStringPoolchecks if it's already stored"abc", and if so, just hands that address back- Otherwise,
StringPooladds it to a dictionary along with the base address + the total byte length stored so far—the address of this new string in the pool StringPoolhands that address back- When all the code is finished compiling, we create an
rodatasection with the giant concatenated string produced byStringPool, stored at the string pool base address (retroactively making all the addressesStringPoolhanded out valid)
Lexer (compiler.py:98)
The Lexer class is complex, because lexing C is complex ((\\([\\abfnrtv'"?]|[0-7]{1,3}|x[A-Fa-f0-9]{1,2})) is a real regex in that code for character escapes), but conceptually simple: the lexer marches along identifying what the token at the current position is.
The caller can peek that token, or it can use next to tell the lexer to advance, "consuming" that token.
It can also use try_next to conditionally advance only if the next token is a certain kind—basically, try_next is a shortcut for if self.peek().kind == token: return self.next().
There's some additionally complexity because of something called the "lexer hack".
Essentially, when parsing C you want to know if something is a type name or variable name (because that context matters for compiling certain expressions), but there's no syntactic distinction between them: int int_t = 0; is perfectly valid C, as is typedef int int_t; int_t x = 0;.
To know if an arbitrary token int_t is a type name or a variable name, we need to feed type information from the parsing/codegen stage back into the lexer.
This is a giant pain for regular compilers that want to keep their lexer, parser, and codegen modules pure and platonically separate, but it's actually not very hard for us!
I'll explain it more when we get to the typedef section, but basically we just keep types: set[str] in Lexer, and when lexing, check if a token is in that set before giving it a token kind:
if m := re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*", self.src[self.loc :]):
tok = m.group(0)
...
# lexer hack
return Token(TOK_TYPE if tok in self.types else TOK_NAME, tok, self.line)
CType (compiler.py:201)
This is just a dataclass for representing information about a C type, like you'd write in int **t or short t[5] or char **t[17], minus the t.
It contains:
- the type's name (with any typedefs resolved), such as
intorshort - what level of pointer it is (
0= not a pointer,1=int *t,2=int **t, and so on) - what the array size is (
None= not an array,0=int t[0],1=int t[1], and so on)
Notably, as mentioned before, this type only supports single-level arrays, and not nested arrays like int t[5][6].
FrameVar and StackFrame (compiler.py:314)
These classes handle our C stack frames.
As I mentioned before, because you can't take references to the WASM stack, we have to manually handle the C stack, we can't use the WASM one.
To set up the C stack, the prelude emitted in __main__ sets up a global __stack_pointer variable, and then every function call decrements that by however much space the function needs for its parameters and local variables—calculated by that function's StackFrame instance.
I'll go over how that calculation works in more detail when we get to parsing functions, but essentially, each parameter and local variable gets a slot in that stack space, and increases StackFrame.frame_size (and thus the offset of the next variable) depending on its size.
The offset, type information, and other data for each parameter and local variable are stored in a FrameVar instance, in StackFrame.variables, in order of declaration.
ExprMeta (compiler.py:344)
This final dataclass is used to track whether the result of an expression is a value or a place. We need to keep track of this distinction in order to handle certain expressions differently based on how they're used.
For example, if you have a variable x of type int, it can be used in two ways:
x + 1wants the value ofx, say1, to operate on&xwants the address ofx, say0xcafedead
When we parse the x expression, we can easily fetch the address from the stack frame:
# look the variable up in the `StackFrame`
var, offset = frame.get_var_and_offset(varname)
# put the base address of the C stack on top of the WASM stack
emit(f"global.get $__stack_pointer")
# add the offset (in the C stack)
emit(f"i32.const {offset}")
emit("i32.add")
# the address of the variable is now on top of the WASM stack
But now what?
If we i32.load this address to get the value, then &x will have no way to get the address.
But if we don't load it, then x + 1 will try to add one to the address, resulting in 0xcafedeae instead of 2!
That's where ExprMeta comes in: we leave the address on the stack, and return an ExprMeta indicating this is a place:
return ExprMeta(True, var.type)
Then, for operations like + that always want to operate on values instead of places, there's a function load_result that turns any places into values:
def load_result(em: ExprMeta) -> ExprMeta:
"""Load a place `ExprMeta`, turning it into a value
`ExprMeta` of the same type"""
if em.is_place:
# emit i32.load, i32.load16_s, etc., based on the type
emit(em.type.load_ins())
return ExprMeta(False, em.type)
...
# in the code for parsing `+`
lhs_meta = load_result(parse_lhs())
...
Meanwhile, an operation like & just doesn't load the result, and instead leaves the address on the stack: in an important sense, & is a no-op in our compiler, since it doesn't emit any code!
if lexer.try_next("&"):
meta = prefix()
if not meta.is_place:
die("cannot take reference to value", lexer.line)
# type of &x is int* when x is int, hence more_ptr
return ExprMeta(False, meta.type.more_ptr())
Note also that, despite being an address, the result of & isn't a place! (The code returns an ExprMeta with is_place=False.)
The result of & should be treated like a value, since &x + 1 should add 1 (or rather, sizeof(x)) to the address.
That's why we need the place/value distinction, since just "being an address" isn't enough to know whether the result of an expression should be loaded.
OK, enough about helper classes. Let's move on to the meat of codegen!
Parsing and code generation
The general control flow of the compiler goes like this:

The blue rectangles represent the main functions of the compiler—__main__, compile(), global_declaration(), statement(), and expression().
The long chain of squares at the bottom shows the operator precedence—most of those functions are automatically generated by a higher-order function, however!
I'll go through the blue squares one-by-one and explain anything interesting in each.
__main__ (compiler.py:827)
This one is pretty short and dull. Here it is in full:
if __name__ == "__main__":
import fileinput
with fileinput.input(encoding="utf-8") as fi:
compile("".join(fi)) # todo: make this line-at-a-time?
Clearly I never finished that TODO!
The only really interesting thing here is the fileinput module, which you may not have heard of.
From the module docs,
Typical use is:
import fileinput for line in fileinput.input(encoding="utf-8"): process(line)This iterates over the lines of all files listed in sys.argv[1:], defaulting to sys.stdin if the list is empty. If a filename is '-' it is also replaced by sys.stdin and the optional arguments mode and openhook are ignored. To specify an alternative list of filenames, pass it as the argument to input(). A single file name is also allowed.
This means, technically, c500 supports multiple files!
(If you don't mind them all being concatenated and having messed-up line numbers :-) fileinput is actually fairly sophisticated and has a filelineno() method, I just didn't use it for space reasons.)
compile() (compiler.py:805)
compile() is the first interesting function here, and is short enough to also include verbatim:
def compile(src: str) -> None:
# compile an entire file
with emit.block("(module", ")"):
emit("(memory 3)")
emit(f"(global $__stack_pointer (mut i32) (i32.const {PAGE_SIZE * 3}))")
emit("(func $__dup_i32 (param i32) (result i32 i32)")
emit(" (local.get 0) (local.get 0))")
emit("(func $__swap_i32 (param i32) (param i32) (result i32 i32)")
emit(" (local.get 1) (local.get 0))")
global_frame = StackFrame()
lexer = Lexer(src, set(["int", "char", "short", "long", "float", "double"]))
while lexer.peek().kind != TOK_EOF:
global_declaration(global_frame, lexer)
emit('(export "main" (func $main))')
# emit str_pool data section
emit(f'(data $.rodata (i32.const {str_pool.base}) "{str_pool.pooled()}")')
This function handles emitting the module level prelude.
First, we emit a pragma for the WASM VM to reserve 3 pages of memory ((memory 3)), and we set the stack pointer to start at the end of that reserved region (it will grow downwards).
Then, we define two stack manipulation helpers __dup_i32 and __swap_i32.
These should be familiar if you've ever used Forth: dup duplicates the item on top of the WASM stack (a -- a a), and swap swaps the position of the top two items on the WASM stack (a b -- b a).
Next, we initialize a stack frame to hold the global variables, initialize the lexer with the built-in typenames for the lexer hack, and chew up global declarations until we run out!
Finally, we export main and dump the string pool.
global_declaration() (compiler.py:743)
This function is too long to inline the whole thing, but the signature looks like this:
def global_declaration(global_frame: StackFrame, lexer: Lexer) -> None:
# parse a global declaration -- typedef, global variable, or function.
...
It handles typedefs, global variables, and functions.
Typedefs are cool, since this is where the lexer hack happens!
if lexer.try_next("typedef"):
# yes, `typedef int x[24];` is valid (but weird) c
type, name = parse_type_and_name(lexer)
# lexer hack!
lexer.types.add(name.content)
typedefs[name.content] = type
lexer.next(";")
return
We reuse a general type-name parsing tool since typedefs inherit all of C's weird "declaration reflects usage" rules, which is convenient for us. (and less so for the perplexed newbie!) Then we inform the lexer we've discovered a new type name, so that in the future that token will be lexed as a type name instead of a variable name.
Finally for typedefs, we store the type in the global typedef registry, consume the trailing semicolon, and return back to compile() for the next global declaration.
Importantly, the type we store is a whole parsed type, since if you do typedef int* int_p; and then later write int_p *x, x should get a resulting type of int**—the pointer level is additive!
That means we can't just store the base C typename, and instead need to store an entire CType.
If the declaration wasn't a typedef, we parse a variable type and name.
If we find a ; token we know it's a global variable declaration (since we don't support global initializers).
In that case, we add the global variable to the global stack frame and bail.
if lexer.try_next(";"):
global_frame.add_var(name.content, decl_type, False)
return
If there's no semicolon, however, we're definitely dealing with a function. To generate code for a function, we need to:
- Make a new
StackFramefor the function, namedframe - Then, parse all the parameters and store them in the frame with
frame.add_var(varname.content, type, is_parameter=True) - After that, parse all the variable declarations with
variable_declaration(lexer, frame), which adds them toframe - Now we know how large the function's stack frame needs to be (
frame.frame_size), so we can start emitting the prelude! - First, for all the parameters in the stack frame (added with
is_parameter=True), we generate WASMparamdeclarations so the function can be called with the WASM calling convention (passing the parameters on the WASM stack):
for v in frame.variables.values():
if v.is_parameter:
emit(f"(param ${v.name} {v.type.wasmtype})")
- Then, we can emit a
resultannotation for the return type, and adjust the C stack pointer to make space for the function's parameters and variables:
emit(f"(result {decl_type.wasmtype})")
emit("global.get $__stack_pointer")
# grow the stack downwards
emit(f"i32.const {frame.frame_offset + frame.frame_size}")
emit("i32.sub")
emit("global.set $__stack_pointer")
- For each parameter (in reverse order, because stacks), copy it from the WASM stack to our stack:
for v in reversed(frame.variables.values()):
if v.is_parameter:
emit("global.get $__stack_pointer")
emit(f"i32.const {frame.get_var_and_offset(v.name)[1]}")
emit("i32.add")
# fetch the variable from the WASM stack
emit(f"local.get ${v.name}")
# and store it at the calculated address in the C stack
emit(v.type.store_ins())
- Finally, we can call
statement(lexer, frame)in a loop to codegen all the statements in the function, until we hit the closing bracket:
while not lexer.try_next("}"):
statement(lexer, frame)
- Bonus step: we assume the function will always have a
return, so weemit("unreachable")so the WASM analyzer doesn't freak out.
Whoof!
That was a lot.
But that's all for functions, and thus for global_declaration(), so let's move on to statement().
statement() (compiler.py:565)
There's a lot of code in statement().
However, most of it is fairly repetitive, so I'll just explain while and for, which should give a good overview.
Remember how WASM doesn't have jumps, and instead has structured control flow? That's relevant now.
First, let's see how it works with while, where it's not too much trouble.
A while loop in WASM looks like this:
block
loop
;; <test>
i32.eqz
br_if 1
;; <loop body>
br 0
end
end
As you can see, there are two types of blocks—block and loop (there's also an if block type, which I didn't use).
Each encloses some number of statements and then ends with end.
Inside a block, you can break with br, or conditionally based on the top of the WASM stack with br_if (there's also br_table, which I didn't use).
The br family takes a labelidx parameter, here either 1 or 0, which is what level of block the operation applies to.
So in our while loop, the br_if 1 applies to the outer block—index 1, while the br 0 applies to the inner block—index 0. (indices are always relative to the instruction in question—0 is the innermost block to that instruction.)
Finally, the last rule to know is that a br in a block jumps forwards, to the end of the block, whereas a br in a loop jumps backwards, to the beginning of the loop.
So hopefully the while loop code makes sense now! Looking at it again,
block
loop
;; <test>
i32.eqz
;; if test == 0, jump forwards (1 = labelidx of the `block`),
;; out of the loop
br_if 1
;; <loop body>
;; unconditionally jump backwards (0 = labelidx of the `loop`).
;; to the beginning of the loop
br 0
end
end
In more normal assembly, this would correspond to:
.loop_start
;; <test>
jz .block_end
;; <loop body>
jmp .loop_start
.block_end
But with jumps, you can express things that you can't (easily) in WASM—for example, you could jump into the middle of a block.
(This mainly is an issue for compiling C's goto, which I didn't even attempt—there's an algorithm that can transform any code using goto into an equivalent program using structured control flow, but it's complicated and I don't think it would work with our single-pass approach.)
But for while loops, this isn't too bad. All we have to do is:
# `emit.block` is a context manager to emit the first parameter ("block" here),
# and then the second ("end") on exit
with emit.block("block", "end"):
with emit.block("loop", "end"):
# emit code for the test, ending with `i32.eqz`
parenthesized_test()
# emit code to exit the loop if the `i32.eqz` was true
emit("br_if 1")
# emit code for the body
bracketed_block_or_single_statement(lexer, frame)
# emit code to jump back to the beginning
emit("br 0")
With for loops though, it gets nasty. Consider a for loop like this:
for (i = 0; i < 5; i = i + 1) {
j = j * 2 + i;
}
The order the parts of the for loop will be seen by the lexer/code generator is:
i = 0i < 5i = i + 1j = j * 2 + i
But the order we need to put them in the code, to work with WASM's structured control flow, is:
block
;; < code for `i = 0` (1) >
loop
;; < code for `i < 5` (2) >
br_if 1
;; < code for `j = j * 2 + i` (4!) >
;; < code for `i = i + 1` (3!) >
br 0
end
end
Notice that 3 and 4 are inverted in the generated code, making the order 1, 2, 4, 3. This is a problem for a single pass compiler! Unlike a normal compiler, we can't store the advancement statement for later. Or… can we?
How I ended up handling this is by making the lexer cloneable, and re-parsing the advancement statement after parsing the body. Essentially, the code looks like:
elif lexer.try_next("for"):
lexer.next("(")
with emit.block("block", "end"):
# parse initializer (i = 0)
# (outside of loop since it only happens once)
if lexer.peek().kind != ";":
expression(lexer, frame)
emit("drop") # discard result of initializer
lexer.next(";")
with emit.block("loop", "end"):
# parse test (i < 5), if present
if lexer.peek().kind != ";":
load_result(expression(lexer, frame))
emit("i32.eqz ;; for test")
emit("br_if 1 ;; exit loop")
lexer.next(";")
# handle first pass of advancement statement, if present
saved_lexer = None
if lexer.peek().kind != ")":
saved_lexer = lexer.clone()
# emit.no_emit() disables code output inside of it,
# so we can skip over the advancement statement for now
# to get to the for loop body
with emit.no_emit():
expression(lexer, frame)
lexer.next(")")
# parse body
bracketed_block_or_single_statement(lexer, frame)
# now that we parsed the body, go back and re-parse
# the advancement statement using the saved lexer
if saved_lexer != None:
expression(saved_lexer, frame)
# jump back to beginning of loop
emit("br 0")
As you can see, the hack is to save the lexer, then use that to go back and handle the advancement statement later, instead of saving the syntax tree like a normal compiler would. Not very elegant—compiling for loops is probably the gnarliest code in the compiler—but it works well enough!
The other parts of statement() are mostly similar, so I'll skip over them to get to the last main part of the compiler—expression().
expression() (compiler.py:375)
expression() is the last big method in the compiler, and it handles parsing expressions, as you might expect.
It contains many inner methods, one for each precedence level, each returning the ExprMeta struct described earlier (which handle the "place vs value" distinction and can be turned into a value using load_result).
The bottom of the precedence stack is value() (somewhat confusingly named, since it can return ExprMeta(is_place=True, ...)).
It handles constants, parenthesized expressions, function calls, and variable names.
Above that, the basic pattern for a precedence level is a function like this:
def muldiv() -> ExprMeta:
# lhs is the higher precedence operation (prefix operators, in this case)
lhs_meta = prefix()
# check if we can parse an operation
if lexer.peek().kind in ("*", "/", "%"):
# if so, load in the left hand side
lhs_meta = load_result(lhs_meta)
# grab the specific operator
op_token = lexer.next()
# the right hand side should use this function, for e.g. `x * y * z`
load_result(muldiv())
# emit an opcode to do the operation
if op_token == "*":
emit(f"i32.mul")
elif op_token == "/":
emit(f"i32.div_s")
else: # %
emit(f"i32.rem_s")
# mask down the result if this is a less-than-32bit type
mask_to_sizeof(lhs_meta.type)
# we produced a value (is_place=False)
return ExprMeta(False, lhs_meta.type)
# if we didn't find a token, just return the left hand side unchanged
return lhs_meta
In fact, this pattern is so consistent that most operations, including muldiv, aren't written out, but instead defined by a higher-order function makeop:
# function for generating simple operator precedence levels from declarative
# dictionaries of { token: instruction_to_emit }
def makeop(
higher: Callable[[], ExprMeta], ops: dict[str, str], rtype: CType | None = None
) -> Callable[[], ExprMeta]:
def op() -> ExprMeta:
lhs_meta = higher()
if lexer.peek().kind in ops.keys():
lhs_meta = load_result(lhs_meta)
op_token = lexer.next()
load_result(op())
# TODO: type checking?
emit(f"{ops[op_token.kind]}")
mask_to_sizeof(rtype or lhs_meta.type)
return ExprMeta(False, lhs_meta.type)
return lhs_meta
return op
muldiv = makeop(prefix, {"*": "i32.mul", "/": "i32.div_s", "%": "i32.rem_s"})
...
shlr = makeop(plusminus, {"<<": "i32.shl", ">>": "i32.shr_s"})
cmplg = makeop(
shlr,
{"<": "i32.lt_s", ">": "i32.gt_s", "<=": "i32.le_s", ">=": "i32.ge_s"},
CType("int"),
)
cmpe = makeop(cmplg, {"==": "i32.eq", "!=": "i32.ne"}, CType("int"))
bitand = makeop(cmpe, {"&": "i32.and"})
bitor = makeop(bitand, {"|": "i32.or"})
xor = makeop(bitor, {"^": "i32.xor"})
...
Only a few operations with special behavior need to be defined explicitly, like plusminus which needs to handle the nuances of C pointer math.
And that's it! That's the last main piece of the compiler.
Wrapping up...
That's been our tour of the C compiler in 500 lines of Python! Compilers have a reputation for being complex—GCC and Clang are massive, and even TCC, the Tiny C Compiler, is tens of thousands of lines of code—but if you're willing to sacrifice code quality and do everything in a single pass, they can be surprisingly compact!
I'd be interested to hear if you write your own single-pass compiler—maybe for a custom language? I think this kind of compiler could potentially be a great stage0 for a self-hosted language, since it's so simple.
Next time, this blog will be back to regularly-scheduled LLM posting with a post about making a small transformer by hand!
MODEL = {
# EMBEDDING USAGE
# P = Position embeddings (one-hot)
# T = Token embeddings (one-hot, first is `a`, second is `b`)
# V = Prediction scratch space
#
# [P, P, P, P, P, T, T, V]
"wte": np.array(
# one-hot token embeddings
[
[0, 0, 0, 0, 0, 1, 0, 0], # token `a` (id 0)
[0, 0, 0, 0, 0, 0, 1, 0], # token `b` (id 1)
]
),
"wpe": np.array(
# one-hot position embeddings
[
[1, 0, 0, 0, 0, 0, 0, 0], # position 0
[0, 1, 0, 0, 0, 0, 0, 0], # position 1
[0, 0, 1, 0, 0, 0, 0, 0], # position 2
[0, 0, 0, 1, 0, 0, 0, 0], # position 3
[0, 0, 0, 0, 1, 0, 0, 0], # position 4
]
),
...: ...
}
If that sounds interesting, or you want to see more posts like this, consider following me on Twitter or subscribing to my mailing list to get updates on new posts!
If you have thoughts about this post, please feel free to get in touch! (Even if you just want to say "that was cool" or want to ask a clarifying question—don't feel like it needs to be capital-I-Important!)
And if you're still around, you must really like the blog, so here's some more stuff to check out :-)
- My other blog posts, such as:
- My other projects, including my short fiction
- My Twitter
Technically, 500 lines not counting comments, docstrings, and whitespace, as measured by sloccount:
$ sloccount compiler.py | grep python:
python: 500 (100.00%)
I didn't count comments since I didn't want to give myself an incentive to not write them.
The code is also formatted with black: there aren't any 400-character-long lines here!
I actually originally set out to explain the entire compiler, line-by-line. I wrote 10,000 words and only got to variable declarations. I wrote an entire literate programming environment. This yak wasn't just shaved, it was skinned, tanned, and constructed into a yurt of my own madness. Needless to say, that draft will not be seeing the light of day.