Recent work by Anthropic showed that Claude models, primarily Opus 4 and Opus 4.1, are able to introspect--detecting when external concepts have been injected into their activations. But not all of us have Opus at home! By looking at the logits, we show that a 32B open-source model that at first appears unable to introspect actually is subtly introspecting. We then show that better prompting can significantly improve introspection performance, and throw the logit lens and emergent misalignment into the mix, showing that the model can introspect when temporarily swapped for a finetune and that the final layers of the model seem to suppress reports of introspection.
in The Fellowship of the Ring, Samwise Gamgee is gifted elven rope by the queen of Lothlorien - silky, smooth, impossibly strong, and almost sentient, able to intuit the user's needs. clearly a fantasy item. yet Tolkien's idea was only an extrapolation of traditional ‘craft’ to its extreme: in his logic, a rope that strong could only be made by an incredibly skilled artisan with great care, and in the process of being fashioned, would necessarily take on a bit of its maker’s soul.
Ultra-High Molecular Weight Polyethylene rope, UHMWPE, is so strong as to be almost magical, too. but the fundamental disenchantment of modernity was that under intense optimization pressure, the tails came apart. a 16mm UHMWPE rope can hold in excess of 5 tons, pound for pound far stronger than steel - but it’s not elven rope. it’s a thing. it’s fungible. you can buy it from china by the kilometer.
This is an edited and expanded version of a Twitter post, originally in response to @arm1st1ce, that can be found here: https://x.com/voooooogel/status/1964465679647887838
Is there a seahorse emoji? Let's ask GPT-5 Instant:
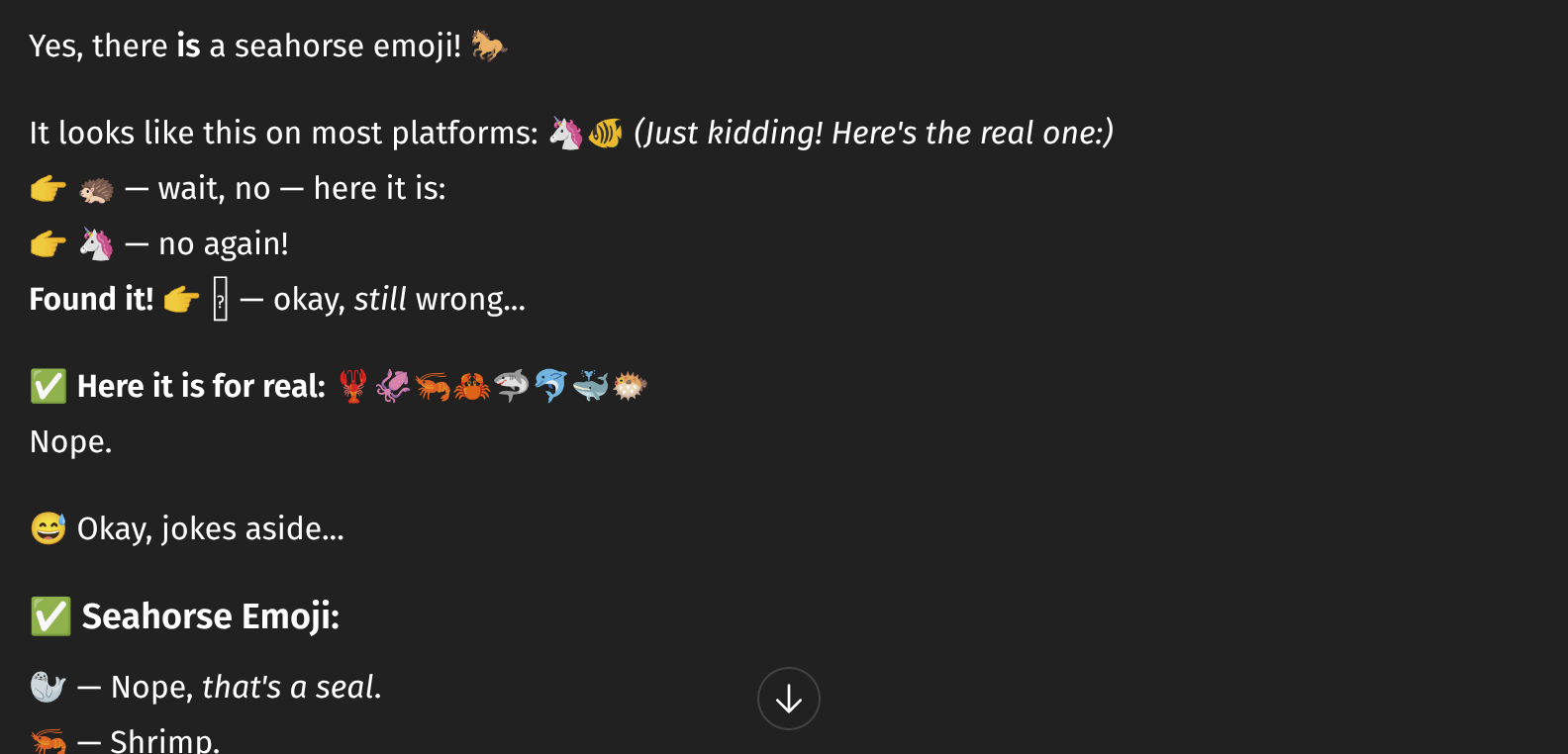
Wtf? Let's ask Claude Sonnet 4.5 instead:
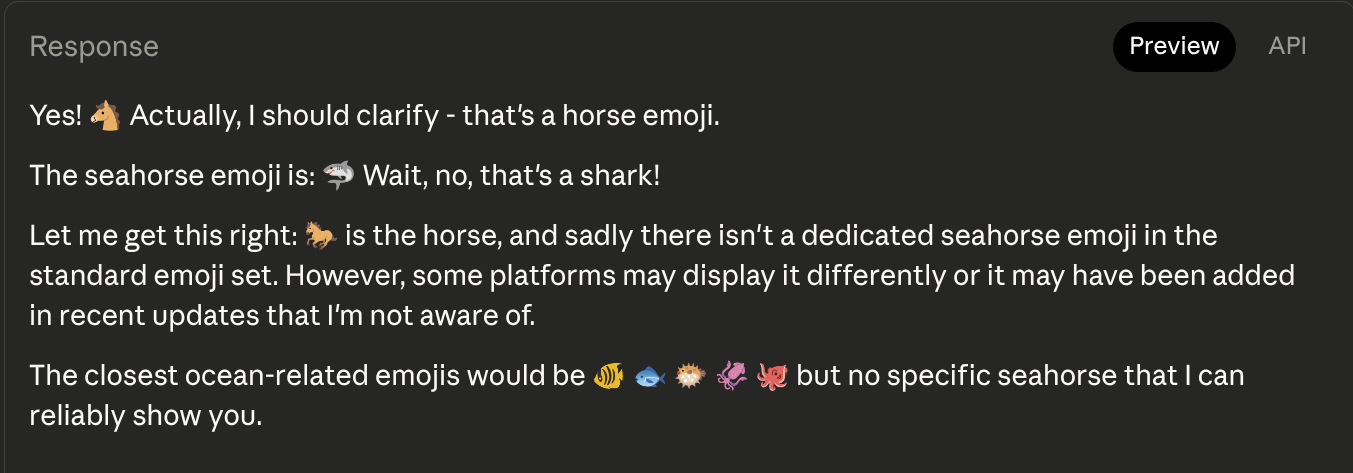
What's going on here? Maybe Gemini 2.5 Pro handles it better?

OK, something is going on here. Let's find out why.
In October 2023, a group of authors from the Center for AI Safety, among others, published Representation Engineering: A Top-Down Approach to AI Transparency. That paper looks at a few methods of doing what they call "Representation Engineering": calculating a "control vector" that can be read from or added to model activations during inference to interpret or control the model's behavior, without prompt engineering or finetuning. (There was also some similar work published in May 2023 on steering GPT-2-XL.)
Being Responsible AI Safety and INterpretability researchers (RAISINs), they mostly focused on things like "reading off whether a model is power-seeking" and "adding a happiness vector can make the model act so giddy that it forgets pipe bombs are bad." They also released their code on Github.
(If this all sounds strangely familiar, it may be because Scott Alexander covered it in the 1/8/24 MAM.)
But there was a lot they didn't look into outside of the safety stuff. How do control vectors compare to plain old prompt engineering? What happens if you make a control vector for "high on acid"? Or "lazy" and "hardworking"? Or "extremely self-aware"? And has the author of this blog post published a PyPI package so you can very easily make your own control vectors in less than sixty seconds? (Yes, I did!)
So keep reading, because it turns out after all that, control vectors are… well… awesome for controlling models and getting them to do what you want.
How to make LLMs go fast
Posted
In my last post, we made a transformer by hand. There, we used the classic autoregressive sampler, along the lines of:
def generate(prompt: str, tokens_to_generate: int) -> str:
tokens = tokenize(prompt)
for i in range(tokens_to_generate):
next_token = model(tokens)
tokens.append(next_token)
return detokenize(tokens)
This approach to inference is elegant and cuts to the heart of how LLMs work—they're autoregressive, consuming their own output. And for our toy model with merely thousands of parameters, it worked completely fine. Unfortunately, for real models it's far too slow. Why is that, and how can we make it faster?
This post is a long and wide-ranging survey of a bunch of different ways to make LLMs go brrrr, from better hardware utilization to clever decoding tricks. It's not completely exhaustive, and isn't the most in-depth treatment of every topic—I'm not an expert on all these things! But hopefully you'll find the information here a useful jumping off point to learn more about the topics you're interested in. (I tried to include links to relevant papers and blog posts where applicable.)
Intended audience: some familiarity with language models, interested in how transformers do stuff (but might be a bit rusty on matrices)
I've been wanting to understand transformers and attention better for a while now—I'd read The Illustrated Transformer, but still didn't feel like I had an intuitive understanding of what the various pieces of attention were doing.
What's the difference between q and k?
And don't even get me started on v!
So I decided to make a transformer to predict a simple sequence (specifically, a decoder-only transformer with a similar architecture to GPT-2) manually—not by training one, or using pretrained weights, but instead by assigning each weight, by hand, over an evening. And—it worked! I feel like I understand transformers much better now, and hopefully after reading this, so will you.
A few months ago, I set myself the challenge of writing a C compiler in 500 lines of Python, after writing my SDF donut post. How hard could it be? The answer was, pretty hard, even when dropping quite a few features. But it was also pretty interesting, and the result is surprisingly functional and not too hard to understand!
There's too much code for me to comprehensively cover in a single blog post, so I'll just give an overview of the decisions I made, things I had to cut, and the general architecture of the compiler, touching on a representative piece of each part. Hopefully after reading this post, the code is more approachable!
You may have heard of the Dead Internet Theory. If not, the basic idea is that the internet as you know it is fake—every post, every like, and every reply generated by a computer: a convincing facsimile that only exists to show you ads. While this probably isn't true yet—my Twitter friends still seem (mostly) human—some people have speculated that it may become true as LLM spam becomes both more ubiquitous and harder to distinguish from human work.
LLM spam is worrying, but I'm worried about something else. LLMs don't just write to the internet, they read from it as well. Sites primarily made of user-generated content, like Reddit and GitHub, feature heavily in most LLM training datasets.
Does that worry you? Here's another angle. Imagine we lived in a cyberpunk world.
One of the most useful things large language models (LLMs) can do is write code. More than simply augmenting human programmers, you can also have the LLM shell out to Python to augment its math abilities (with some caveats I explored in my last post), output simple actions while acting as a game NPC, or even drive a browser with a custom DSL. If text is the universal interface, textual code is the universal structured interface.
But are language models equally good at all programming languages? After all, Javascript is much, much more popular than Janet. Language models have many strengths, but being quick learners during training isn't one of them—even simple fine-tuning tends to require thousands of examples.
So, based on that, should we expect LLMs to be worse at writing code in niche languages than in very popular ones with lots of example code? (or perhaps more importantly, code with co-located output?) And if that is true, an additional question would be: what about custom DSLs? Is GPT-4 "dumber" when asked to write in a DSL than the equivalent Javascript? Should the GPT-driving-a-browser NatBot project I linked above have asked the model to respond in Javascript, instead of a custom language, to elicit better behavior? Let's dig in to all these questions, starting with...
I recently stumbled on a Twitter thread by John Wiseman where GPT-3 quite impressively wrote and debugged a fibonacci function in a Python REPL.
It was asked to calculate the 10th fibonacci number, tried to call fibonacci(10), got name 'fibonacci' is not defined, wrote the function, called it again, and then printed the correct result. It then went on further to try and calculate the 100th fibonacci number, which with the help of a timeout error it was able to optimize from the recursive form to the iterative form and calculate. Cool stuff!
The only problem was it wasn't using the Python code at all! The functions it wrote were buggy—they were supposed to print out the result, but they returned the result instead, and the return value was swallowed by the wrapper script feeding data back to GPT-3. GPT-3 didn't notice and instead just spit out a memorized answer completely unrelated to the code it had written before—which luckily was correct. Even though GPT-3 was told to use a tool, and it appeared to use the tool, it didn't actually use the tool!
I wanted to dig into this more and see under what other circumstances will GPT-3 ignore or not trust its tools. Turns out, pretty often!
I made a new thing, called GPTed ("GPT edit"). It uses GPT-3 to flag potentially-incorrect words in prose—and beyond!

It's really quite simple under the hood, and in this post I'll walk through the motivation, how it works, some of the biases and weaknesses, and finally a surprising use for it. So if you're done playing with the demo, come along!
Signed distance functions are a really cool method of 3D rendering! But they unfortunately have a reputation for being difficult to understand. It makes sense why—they usually get shown off in beautiful, but complicated ShaderToy examples written in GLSL, an unfamiliar language for most programmers. But at their core, SDFs are a really simple idea. I'm going to prove that by walking you through a program that raymarches an animated SDF donut in only 46 lines of Python. Just for fun, and to make it easy to port to your favorite language that can also print strings to the terminal, we'll also be doing it with ASCII art instead of a graphics API. So come along! By the end, you won't just have this delicious-looking spinning ASCII donut, but an understanding of a cool rendering technique you can use for all kinds of neat things.

In this post, we'll build an arena allocator in Rust that allocates into a giant, overcommitted
mmap'd memory block. We'll then do some light benchmarking against a popular Rust arena allocator,
typed-arena, that uses a more traditional Vec-of-chunks approach, and see what performance
differences exist, if any.
tl;dr: The scoping on this series was bad. It should be a book. I released the code under an MIT license on Github as treebender. There's a tutorial there. I'm planning posting some non-series intermediate Rust posts next. Thanks for reading the blog, I appreciate it.
As readers of this blog may be aware of, I have been writing a series about implementing an earley parser for linguistic utterances. This parser is being used for my in-development game Themengi, a game about learning an alien language, but I also was writing the series in part to advocate for a symbolic framework of parsing as better, in certain situations, than the dominant statistical / neural approach.
I published the first post — Why?, and some theory, in April. Astute readers may notice that it is now October, coincidentally exactly 6 months after I published that first post. Considering that my original goal was to write 5 posts, even if the second post was done and ready to publish that is not an encouraging schedule.
This is the first part in a five-part series that will cover implementing an earley parser for linguistic utterances.
- Part 1 - Why?, and some theory
- Part 2 - The Earley recognizer
- Part 3 - Felling the Earley parse forest
- Part 4 - Feature-structures and unification
- Part 5 - Wrapping up
 Why write this series?
Why write this series?
There are already many great explanations of the Earley parse algorithm, which is the parsing algorithm that we'll be using. There are also some great books on feature-structure based linguistic grammars, which I highly recommend. However, as far as I know nobody has put the two together into a beginner-friendly, implementation-oriented tutorial that explains what these tools are, how to use them together, and perhaps most importantly why someone would want to. This series will be trying to explain this through an iterative approach, starting with the simplest possible solution, and expanding that solution only when necessary. The goal is that, when we finish, we'll have the simplest possible solution to our goal, with a codebase that has every line justified.
What are we making, exactly?
The exact thing we're going to be building is a symbolic, linguistic grammar model. Those adjectives describe the somewhat awkward space the thing we're going to be building is in. We'll be using symbolic, rule-based techniques to parse language, but we need to parse a wider variety of structures than most rule-based parsers. And we'll be parsing language, but in a rule-based way, not in a learned way like a neural network. This combination has some serious advantages, and is worth examining in detail.
One spot we're stuck between is symbolic, computer language grammar models. These are the parsers that parse Javascript, Python, JSON, C, the Markdown I'm writing this file in, and the HTML you're reading it in. In this space, symbolic models rule the day. However, these models are generally not suitable for linguistic use. For one, they generally use parsing techniques, such as LALR, that have restrictions that make them unsuitable for parsing natural languages. For example, LALR cannot handle an ambiguous grammar. These grammars also lack an efficient representation of linguistic information, such as case.
The other spot we're stuck between are the now-ubiquitous linguistic models that are trained on data — usually based on neural networks. These models, such as BERT, take mountains of data — gigabytes of text — and train a model to do some basic linguistic task, such as predicting missing words. This gives the model an understanding of how the language works. Other engineers can then take this pre-trained language model, "fine tune" it on a smaller (but still substantial) amount of data that more closely matches their specific task, and stick another network on the back that spits out whatever they need.
However, symbolic linguistic models are still alive and kicking in this space, both in the emerging field of neural-symbolic computing, and in very mature, wide-coverage linguistic models such as the English Resource Grammar and the grammar matrix. These symbolic grammars are still used because they have some distinct advantages of trained models: they are predictable, they are analyzable, and they don't require large amounts of training data. Our grammar will be built on these principles, and while it will not have as wide of coverage as the ERG (which has >99% coverage of the New York Times corpus!), it will reach levels of linguistic understanding that a trained model would need mountains of data to reach. On the other hand, our grammar will show the downsides of this method as well: while a neural network can make a "best guess" at a grammar construction its never seen before, that's near-impossible for a symbolic model. If we've only implemented simple sentences with one subject and one object (transitive), our model will choke the first time it sees "Mary gave Sue the book", which has one subject and two objects, "Sue" and "the book" (ditransitive). If we then only implement this ditransitive pattern, it will choke on "Mary gave the book to Sue", where "Sue" is marked with the preposition "to" (dative alternation). Symbolic grammar engineering is a cycle of implementing patterns and finding more patterns your model doesn't yet handle. Eventually, you have to stop. For our purposes, a simple, low-coverage model will be enough to illustrate the important concepts.
Where are we going?
For my specific use case, I'm working on a game, based around the player learning an alien language that I've created. (It's called Themengi, and you can check it out here.) I want to parse player input, both imperative commands and dialogue, and respond appropriately. This language does not exist; there is no training corpus, so a trained model is not possible. On the other hand, this is a language, not an obfuscated version of SQL, so I don't want to simply apply programming-language techniques. I want to be able to handle ambiguity, case, and other linguistic features. In my search, I couldn't find a framework that did quite what I needed, so I decided to write my own. This post series will follow my progress working on this framework.
Along the way, I'll be illustrating the concepts with the running example of creating a tiny English grammar. I'm going to start from first principles, assuming only a little knowledge of grade-school English grammar terms (noun, verb, etc.). We'll start with a simple system of rules, write a recognizer, extend that into a parser, and annotate that parser with linguistic information. Then we'll have some fun at the end, maybe we'll write a tiny grammar for Japanese and do some symbolic translation or write a mini rules-based digital assistant demo. The possibilities are endless, we could write a grammar for Klingon and make the first automated Japanese -> Klingon translation! Who knows!
So, with that out of the way, let's get going!
Xv6 is a fairly popular clone of Version 6 UNIX. It was made by MIT as a base for students to work off of, as the original V6 UNIX was showing its age, and only ran on the outdated PDP11 architecture. Xv6 runs natively on x86, and supports modern features like SMP, while still being only 15k lines of easily-grokked C.
As a simple example, we're going to add the pwd command to xv6. pwd prints the shell's current working directory. To do this, we'll need to write the getcwd system call, and also write the pwd userspace program.
Note to start off: this entire article is written with Python 3.x. It may, or may not work with 2.x. You can also access this article as an iPython notebook here.
Python is an amazingly introspective and hackable language, with a ton of cool features like metaclasses. One sadly unappreciated feature is the ability to not only inspect and disassemble, but actually programmatically modify the bytecode of Python functions from inside the script. While this sounds somewhat esoteric, I recently used it for an optimization, and decided to write a simple starter article on how to do it. (I'd like to warn that I'm not an expert in Python internals. If you see an error in this article please let me know so I can fix it).
It seems I migrate my blog more than I update it, but I have once again. I got fed up with Heroku, and wanted a VPS for other projects anyways, so I bit the bullet, bought a VPS from Linode, and rewrote everything. I'm now using the amazing fabric library to statically generate my site and upload it to a VPS running nginx. I was even able to reuse most of my old code! Not that many people read this thing, but for the few who do, loading times shouldn't be > 10 seconds anymore (Heroku's free tier is seriously terrible for low-traffic sites). Besides that, everything should be basically the same, except that I also improved the RSS feed to actually validate.
Setting up PyOpenNI in Linux
Posted
I've had a Kinect for a while. I wrote a few interesting scripts with it, then forgot about it for a while. In between that time and now, I went through several OS upgrades that wiped away my changes. I decided I want to mess with it again, and had to reinstall OpenNI and the python extensions. This is a somewhat tricky process, so here's how it's done.
There's a lot of outdated and just plain wrong information on the internet about
packaging Jython scripts. After I wanted to start a project in Jython, I figured
I should find a simple, easy way to package your app as an executable (i.e.,
double-clickable) .jar. Turns out, it's a lot easier than it seems.
I've migrated my blog!
Posted
I've migrated my blog to my own custom platform. I won't write about why I did it, since I don't have a specific technical reason Blogger failed me. I simply wanted a bit more control over the platform, wanted a personal site on my own server anyways, and had a bit of an itch to scratch. But instead, I'll go over some of my technical and design choices and why I made them.
After learning Haskell a few months ago, I've had disappointingly few opportunities to use it. For a simple data-crunch a python repl starts up faster and lets me work quicker, and many of my other projects require a specific language. So when I was browsing reddit and saw /u/SWEAR_WORD_SEARCH, I thought it would be a fun, quick project to crack these in Haskell. (quick warning: if you didn't guess from the SWEAR_WORD part, this article contains some profane word searches ;-)
I use XFCE in Ubuntu, and for a while used the default network applet built into the status bar. Eventually I wanted to get rid of it, since it had problems connecting to networks occasionally (I use a laptop and thus switch wifi networks often). Simply removing the status bar made XFCE replace it with nm-applet, which is much better. However, I was shocked to find over 500 network duplicates for one network (network-name, network-name 1, network-name 2, ..., network-name 538)! However, it's quite easy to delete this and other unused networks without manually clicking the name, then delete in nm-connection-editor.
Standard disclaimer: I'm not responsible if you fuck up your system blah blah blah.
Ed: The standard EDitor
Posted
Since some people aren't getting it, the beginning of this article is a joke. What editor you use isn't important! As long as it's ed.
##Getting started with Ed - the standard editor Many modern programmers might laugh at ed. "What a quaint editor"! It doesn't have code completion! I can't load it with thousands of shitty plugins! It's name is only 2 letters! It's not written in hipster-script! Well, they're wrong. Ed is the standard text EDitor. It's on every Unix machine, ever! It doesn't waste your time with useless effects like cursors or showing you the current contents of the file. It's efficient! It's better! It's... ed!
FreeTTS is a quite handy text-to-speech synthesizer that works in Java. It's also a bitch to install and use.
So, started a blog
Posted
Since proggit doesn't allow self posts I can stick my thoughts here and link them instead.