GPTed: using GPT-3 for semantic prose-checking
I made a new thing, called GPTed ("GPT edit"). It uses GPT-3 to flag potentially-incorrect words in prose—and beyond!

It's really quite simple under the hood, and in this post I'll walk through the motivation, how it works, some of the biases and weaknesses, and finally a surprising use for it. So if you're done playing with the demo, come along!
 Can GPT-3 proofread text?
Can GPT-3 proofread text?
GPT-3 is surprisingly good at catching errors in text. You can give it some messed-up text, ask it to figure out what's wrong, and often get a correct response:

It can even pick up on semantic errors. When I was in school, my teachers said it's worth checking your own work because a spellchecker can't tell the difference between "for" and "four", but guess what??

Take that, elementary school! I'm never poorfreadign my writing aagin!<|endoftext|>
Unfortunately, as the mistakes pile up in the sentence, GPT-3 starts to struggle. Though it tried valiantly, it only managed to identify three of the five mistakes here:

(I also had to prompt it for a specific output format to prevent it from just throwing up its hands and rewriting the sentence entirely)
However, if we prompt GPT-3 to just reword the sentence, it fixes all the issues, no sweat:

This proves that GPT-3 does have the ability to identify all the errors in even the worst word-salad sentences. Somewhere inside, the model "knows" which tokens are OK to keep—such as "I" and "to the"—and which need to be replaced.
However, so far there doesn't seem to be a way to get GPT-3 to tell us what's incorrect without it totally rewriting the incorrect text and introducing spurious changes. That kinda sucks. I don't know about you, but I don't really love the GPT writing style—it's kind of… bland and inoffensive1. You can see this in the example above: it reworded the slightly-quirky "but they had none" phrasing into the more predictable "but they were out". And to be fair, of course it did! That's a language model's job, to predict the most likely text. But for proofreading, that's not really what we want.

The output here is worse than wrong: it is boring.
For checking human writing—human writing that has character and tone, that is—we don't want to just rewrite it into boring GPT output. We instead want a more comprehensive version of the first examples, where GPT pointed out the problems without rewriting the sentence. Too bad that's not possible…
Use the logprobs!
OK, obviously it is possible, since I'm writing this post!
The idea is to use some of GPT-3's semi-internal state—its measure of how "certain" it is about a token, which is the token's logprob.
To roughly simplify, a logprob is log(p), where p is the probability of a token occurring at a specific position based on the other tokens in the sentence (a token is a word or part of a word).
Because of the log₂, a logprob of 0 is the maximum value—equivalent to a probability of 1 (100%).
A logprob of -1 is a probability of 0.1, -2 is 0.01, and so on.2
To make this more concrete, here is a table of tokens and the logprobs GPT assigns to those tokens for an arbitrary sentence:
| Token | Logprob |
|---|---|
I | -5.84992 |
'm | -2.3456461 |
going | -4.046307 |
to | -0.06447887 |
the | -3.9299145 |
store | -0.902763 |
We can see that the tokens start out fairly unlikely—there's a lot of words that can start a sentence!—but as the sentence gets more predictable, the probabilities start going up. Note the bigram (two-word pair) "going to" has a very close-to-0 logprob (-0.06) assigned to "to"—converted to a normal probability, it's over 86%! That means any word except "to" in that position would be considered unlikely, and get a correspondingly negative logprob.3
Let's see what the logprobs are for the other tokens in the sentence:
| Token | Logprob |
|---|---|
| … | … |
to | -3.3684485 |
get | -1.4402429 |
milk | -3.1461346 |
, | -3.9721346 |
eggs | -0.503811 |
, | -0.029434223 |
and | -0.23658139 |
demonic | -23.635553 |
summoning | -4.975381 |
supplies | -1.5169595 |
Note that all the tokens are hovering between 0 (100%) and -4 (~0.001%) until demonic, which is a staggering -23.6!
That's <0.000000000000000000001%!
The model really wasn't expecting that token.
Usually the GPT-3 API only returns these logprobs for its own output—whatever text you feed into the model to prompt that output doesn't get returned.
However, if you set "echo": true on the request, the prompt tokens and their associated logprobs will get returned along with the generated completion.
So if we set the maximum completion length to 1 token, we can get back what we really want—the probabilities for each token in the input (along with one dummy output token that we ignore).
OK, here's GPTed for real
I wrapped this in a little prototype I'm calling GPTed (short for "GPT edit").
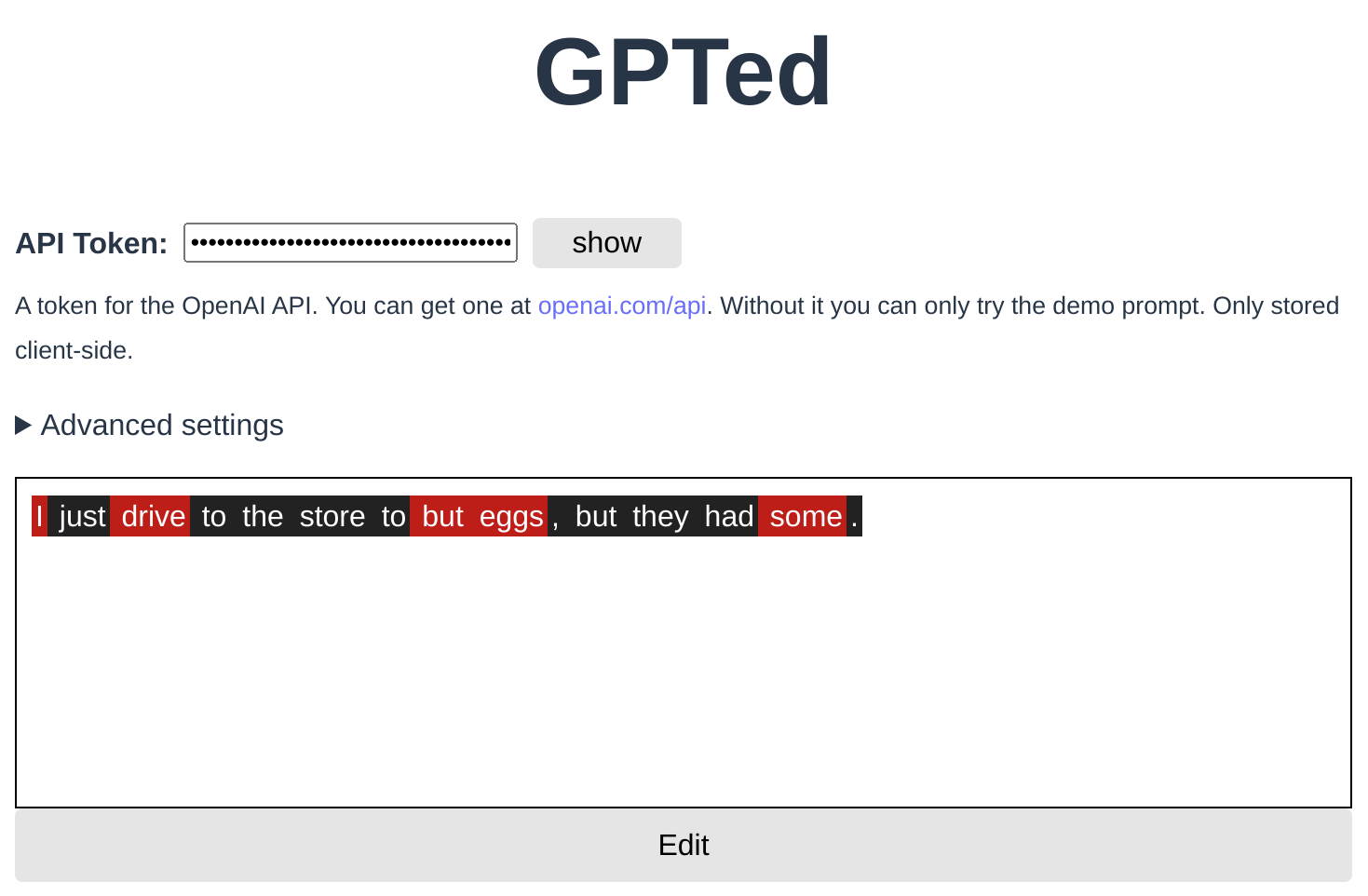
The tokens highlighted in red fall below the configured logprob threshold (-5 by default). You can see it catches all the errors in the sentence—along with a couple false positives (it really dislikes the first word of the input—I should probably add a correction factor).
Just because a token is red doesn't mean it's an error—"demonic" in the table above would also be highlighted in red, as it was quite unlikely in the model's estimation. But in that case, that was the point! It was a subversion. So the idea isn't to "purge the red tokens", but rather to guide the proofreader to double-check each highlighted token and make sure it's unlikely on purpose—instead of on porpoise. (And of course, this all means GPTed or GPT-3 in general can't replace a human editor—replacing human editors is AGI-hard4.)
My editor friend has a filter set up in Word specifically for this because you do NOT want this typo in a book.
Context prompts and dictionaries
Because likely tokens are just what's, well, likely, the model can be a little biased:

GPT thinks "handsome prince" is more likely than "beautiful princess" here, since that's the heterosexual fairy tale trope. Luckily we can fix this! If we pop open "Advanced settings", we can add some context (lesbians exist), which helps GPT predict the tokens better:

Checking "Show whole prompt" will show what's being added—the text in the "Context" box is simply being prepended with "Context:" on the line before the main text.
The astute viewer will have also noticed the dictionary option, which works similarly. Without a dictionary, uncommon names and invented words are flagged:
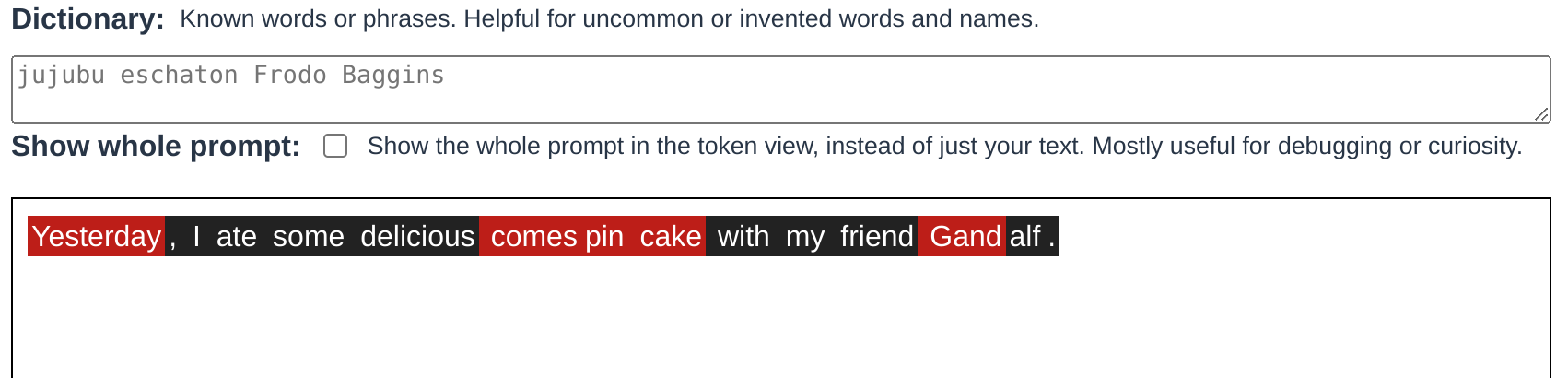
By adding entries to the dictionary, we can prevent those words from being flagged:

Like the context, this just adds the words to a line before the main text to prime GPT to expect them. Nothing fancy!
Shocking twist: it can also code!
Pop quiz! Do you see the bug?
// Context: C code from an image manipulation library.
for (int y = 0; y < HEIGHT; y++) {
for (int x = 0; x < WIDTH; x++) {
buf[y * HEIGHT + x] = 0;
}
}
GPTed does!
![GPTed highlights the "HEIGHT" in "buf[y * HEIGHT + x]"](https://vgel.me/posts/gpted-launch/width-not-height.png)
GPTed correctly picks up that the HEIGHT token (or rather, the first token of that multi-token word) is suspicious—the correct expression is y * WIDTH + x, of course.
Not the hardest bug in the world to catch, but one that tired eyes in a code review could easily slide off of since y means height, right?
Luckily GPT-3 does not get sleepy, it does not stop to rest or eat, it hunts ceaselessly, and it has our best interests at heart <3
In conclusion
Thanks for reading! I hope you give GPTed a try! Let me know if you find anything cool it can do, or weird issues, or if you just wanna chat.
Also, for my dedicated followers, I am still working on that C-compiler-in-500-lines-of-Python post. It's just taking a little while. I'm estimating that it may end up being 20k words at the rate I'm writing… just a silly lil' post… :3
Except when it occasionally is incredibly offensive, of course.
Why use logprobs instead of easier-to-understand probabilities? There's a few different reasons5, but a big one is: gotta go fast! Multiplying probabilities is a common operation, but floating-point multiplication is slow. log(a * b) == log(a) + log(b), which allows multiplications to be performed as significantly-faster additions instead.
Which makes sense—Google Ngrams shows "going to" as almost 8x more common than "going on", the runner up.
"AGI hard" meaning "AI will have to become as smart as a human to do this well", because editing isn't just checking for spelling errors and word misuse. Editing, unless you're writing soulless marketing copy, is about making writing good. Writing is good because of how it interacts with human preferences, society, and culture, and so making writing good requires a human-level understanding of human preferences, society, and culture. The kind of checks this tool can (crudely) help with are important, but they're also the lowest level of what a good editor does.
What other reasons? One is that floating point is bad at representing numbers very close to 0—Google "denormals" for more information on that—so logprobs are useful because they spread out the representation of probabilities from [0, 1] to [-∞, 0]. There's also some stuff around optimization working better on a logarithmic geometry? I'll admit I don't really understand why that's true.6
Guess who just found out they can nest footnotes?